쿠버네티스에서 자주 사용되는 애플리케이션 관련 리소스(PV/PVC, Deployment, Service, HPA) 들을 중심으로 내용을 정리해보겠습니다.
PV & PVC
Kubernetes에서 스토리지를 다루는 대표적인 방식은 PV(PersistentVolume) 와 PVC(PersistentVolumeClaim) 입니다. 이번 글에서는 특히 로컬 스토리지(local, hostPath) 중심으로 PV/PVC가 어떻게 동작하는지, 그리고 실제 운영 환경에서 어떤 방식으로 활용되는지를 살펴보겠습니다.
기본적으로 PVC는 사용자의 저장소 요청이며, PV는 실제 저장소를 제공하는 리소스입니다. PVC는 보통 selector를 통해 PV의 label과 매칭되어 연결됩니다. PVC가 생성되면, 쿠버네티스는 조건에 맞는 PV를 바인딩해 사용하게 됩니다. 보통 PVC의 Selector와 PV의 label로 연결된다.
PV 리소스에는 local이라는 속성이 존재하는데, 이는 특정 노드의 로컬 디스크를 저장소로 사용하는 방식입니다. 이 경우, nodeAffinity 설정을 통해 어떤 노드에서 Pod를 실행할 것인지 명시적으로 지정해주어야 합니다. 예를 들어, 특정 노드의 이름을 지정해 해당 노드에서만 PV가 사용되도록 강제할 수 있습니다. 쿠버네티스에서 노드를 생성하면 기본적으로 아래와 같은 label이 자동으로 생성됩니다
kubernetes.io/hostname: k8s-master
이런 label을 기준으로 nodeAffinity를 설정하여 PV가 바인딩될 노드를 제어하게 됩니다. 여러 개의 워커 노드를 구성한 경우, 각 노드는 각각의 hostname label을 갖고 있으며, 이를 활용하여 스토리지 위치를 지정할 수 있습니다.
로컬 스토리지를 사용하는 경우, PV에 path를 지정하면 해당 경로는 Pod 내의 컨테이너 마운트 경로로 연결됩니다. 즉, 애플리케이션이 컨테이너 내에서 파일을 저장하면, 실제로는 해당 노드의 로컬 디스크에 저장되는 것입니다. 이러한 방식은 다음과 같은 장점이 있습니다.
- Pod가 종료되거나 재시작되더라도, 노드가 유지되는 한 파일은 그대로 보존됩니다.
- 이는 테스트 환경이나 간단한 로컬 운영 환경에서 자주 사용됩니다.
그러나 주의할 점도 있습니다. Pod가 특정 노드에 종속되므로, 노드가 삭제되거나 장애가 발생할 경우 저장된 데이터도 함께 손실될 수 있습니다. 따라서 임시 파일처럼 보존이 필요 없는 경우에는 문제가 없지만, 지속적인 보존이 필요한 데이터라면 주의가 필요합니다.
또 다른 방식으로는, Pod에 직접 volumes: hostPath를 지정하여 특정 노드의 디렉토리를 마운트하는 방법이 있습니다. 이 경우, nodeSelector를 사용하여 해당 hostPath가 존재하는 노드에 Pod를 고정시켜야 합니다.
volumes:
- name: my-volume
hostPath:
path: /data/my-app
type: Directory
하지만 hostPath 방식은 보안 위험이 큽니다. 노드의 파일 시스템을 직접 건드리는 방식이기 때문에, 컨테이너 격리 원칙을 위반할 수 있고, 다른 리소스에 악영향을 줄 가능성도 존재합니다. 그래서 Kubernetes 문서에서는 제한된 경로만 읽기 전용(ReadOnly)으로 마운트하는 방식을 권장하고 있습니다.
운영환경에서는 노드의 디스크 용량이 제한적입니다. 만약 하나의 Pod가 노드의 디스크 공간을 과도하게 사용하다가 해당 노드가 장애를 일으키면, 그 노드에서 실행 중인 다른 Pod들도 함께 영향을 받게 됩니다. 따라서 로컬 디스크에 의존하는 방식은 운영환경에서는 위험할 수 있습니다. 이러한 이유로 NAS(Network Attached Storage) 서버를 통해 데이터를 중앙화하여 보존하기도 합니다. NAS는 네트워크로 공유된 외부 스토리지이며, 노드가 장애를 일으켜도 데이터를 유지할 수 있습니다. 하지만 NAS는 수동으로 마운트해야 하는 경우가 많고, 자동화 및 오케스트레이션 측면에서는 불리합니다.
이를 보완하기 위해 EFS(AWS), NFS, 혹은 Rook, Longhorn 같은 서드파티 스토리지 오퍼레이터를 사용하는 경우가 많습니다.
이러한 도구들은 쿠버네티스 환경에서 스토리지를 자동으로 관리하고 분산 저장 및 복구 기능까지 제공하므로 운영환경에서 선호됩니다.
그럼 왜 굳이 PV, PVC를 써야할까요?
프로젝트를 진행하다 보면 Pod를 생성하는 주체는 개발자인 경우가 많습니다. PVC를 통해 개발자는 “이만큼의 저장 공간이 필요하다”고 요청만 하면 되고, 실제 저장소(PV)는 인프라 담당자가 적절한 리소스를 바인딩해 제공할 수 있습니다. 이러한 구조는 역할 분리와 자동화를 가능하게 해주며, 유연하고 안정적인 인프라 운영을 위한 기반이 됩니다. 또한 서드파티 라이브러리를 작성한다고 해도,PV는 자동 생성되고, 개발자는 PVC와 StorageClass를 통해 저장소를 요청하게 됩니다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-longhorn-pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn
resources:
requests:
storage: 5Gi
이렇게 PVC만 작성하면, Longhorn이 알아서 StorageClass → PV → 실제 볼륨을 자동으로 생성해줍니다. 인프라 담당자는 PV를 따로 안 써도 되지만, 내부적으로 자동으로 생성됩니다.
정리하자면,
- local, hostPath는 테스트 환경이나 특정 앱(Grafana, Loki 등)에서 유용합니다.
- 운영 환경에서는 노드 의존성을 줄이고, 스토리지 이중화 또는 분산 방식을 고려하는 것이 중요합니다.
- PVC/PV 구조는 역할 분리, 자동 바인딩, 유연한 인프라 운영을 가능하게 합니다.
Deployment
애플리케이션의 새로운 버전이 출시되었다고 가정해보겠습니다. 이제 기존 Pod를 종료하고, 새로운 버전의 Pod로 교체해야 합니다. 쿠버네티스는 이러한 과정을 수동으로 처리할 필요 없이, Deployment 오브젝트를 통해 자동으로 관리할 수 있도록 지원합니다. Deployment에는 strategy라는 속성이 있어, 어떤 방식으로 Pod를 업데이트할지 지정할 수 있습니다.
Deployment 내부에는 template이라는 속성이 있으며, 이 안에는 실제로 생성될 Pod의 정의(spec)가 담겨 있습니다. 이 template의 내용이 조금이라도 변경되면, 쿠버네티스는 이를 감지하고 새로운 ReplicaSet을 생성해 업데이트를 진행합니다.
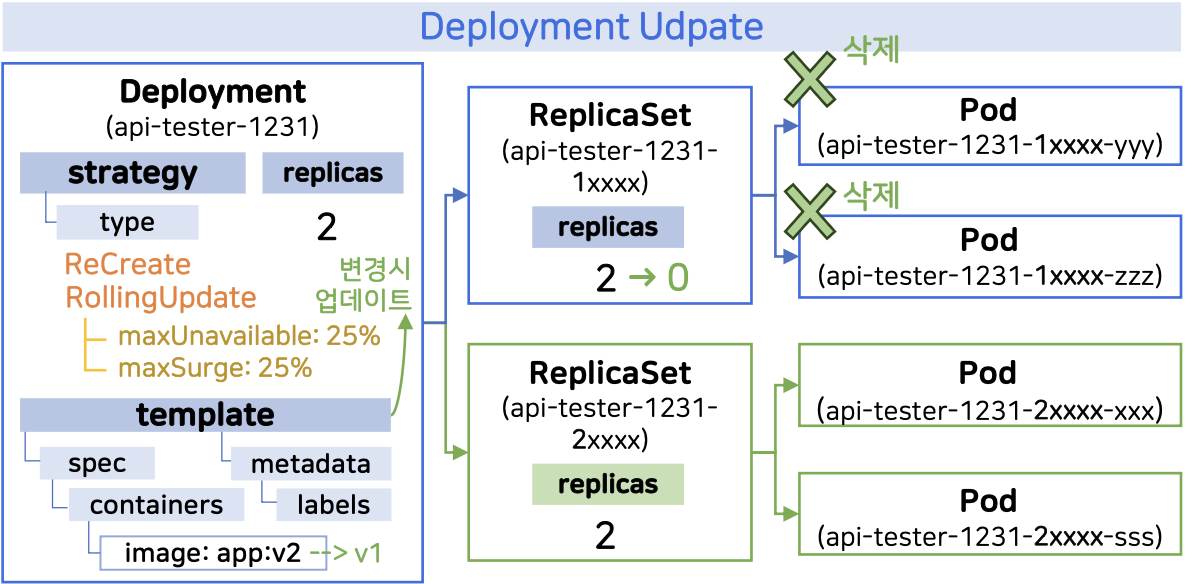
예를 들어 아래와 같이 image 버전이 변경되면 업데이트가 시작됩니다.
spec:
containers:
- name: my-app
image: my-app:v2 # ← v1에서 v2로 변경
Recreate & RollingUpdate
업데이트의 전략에는 2가지가 있습니다.
| Recreate | 기존 Pod를 모두 종료한 뒤, 새 버전의 Pod를 생성 |
| RollingUpdate (기본값) | 기존 Pod를 하나씩 줄이고, 새 Pod를 하나씩 추가하여 점진적으로 교체 |
Recreate의 경우 App마다 기동시간이 달라서, 기동 시간만큼 서비스가 중단이됩니다. 하지만 RollingUpdate의 경우는 업데이트 중 서비스 중단이 없습니다. 하지만 자원 사용량이 늘어납니다.
RollingUpdate에서 설정값 2가지가 있습니다.
- maxUnavailable: 업데이트 중 동시에 비활성화될 수 있는 최대 Pod 개수
- maxSurge: 업데이트 중 추가로 생성 가능한 최대 Pod 개수
예를 들어, replicas가 2이고 maxUnavailable: 0%, maxSurge: 100%이면
- 초기 상태: 기존 버전(v1) Pod가 2개 정상적으로 동작 중
- 새 버전(v2) 배포 시작
- maxSurge: 100% → 기존 replica 2개 기준으로 최대 2개 더 생성 가능
- 즉, v2 버전 Pod 2개 추가 생성 가능
- v2 Pod 2개가 준비 완료되면, 기존 v1 Pod 2개를 종료됩니다.
- maxUnavailable: 0% 이기 때문에 v1이 완전히 종료되기 전까지는 v2가 준비돼 있어야 함
- 결과: 전체적으로 최대 4개의 Pod가 동시에 존재할 수 있습니다.
이를 통해 서비스 중단 없이 점진적으로 새로운 버전의 Pod로 교체할 수 있습니다.
Sevice
Service 오브젝트의 경우, Pod와 통신을 이어주는 핵심 리소스입니다. 쿠버네티스에서 Pod는 언제든지 죽고 재생성되며, 그때마다 IP가 바뀝니다. 그래서 안정적으로 통신하려면, 중간에서 트래픽을 중계하고 관리해주는 Service 리소스가 꼭 필요합니다. Service는 크게 다음과 같은 역할을 수행합니다.
1. Service Publishing: 외부에서 Pod로 트랙픽을 연결해줍니다.
- Pod는 기본적으로 클러스터 외부에서 직접 접근할 수 없습니다.
- Service를 통해 NodePort, LoadBalancer, Ingress 등 외부와 연결되는 창구를 열어줍니다.
- 가장 기본적인 ClusterIP는 내부 통신 전용이지만, 외부로 노출할 때는 NodePort나 LoadBalancer 타입으로 Service를 설정합니다.
2. Service Discovery: 내부 DNS를 이용한 Service 이름으로 API를 호출해줍니다.
- Pod는 재시작될 때마다 IP가 바뀌기 때문에 직접 IP로 통신하면 무조건 깨집니다.
- 대신 Service는 고정된 DNS 이름을 갖고 있어 my-service.my-namespace.svc.cluster.local 같은 방식으로 호출합니다.
- 클러스터 내부 통신은 대부분 이 구조로 진행됩니다.
- API 호출시, 다음과 같이 사용하게 됩니다.
http://service-name.namespace:port/endpoint
3. Service Regitstry & Load Balancing
- Service는 label selector로 연결된 모든 Pod들의 IP를 자동으로 관리합니다.
- 새 Pod가 생기거나 사라져도 자동으로 반영되며, Round Robin 방식으로 트래픽을 분산시킵니다.
- 사용자는 Pod의 개수, IP, 상태를 신경쓸 필요 없이 항상 같은 Service만 바라보면 됩니다.
Service &Pod의 패턴
Pod의 포트가 바뀌어도 Service에 영향이 없도록 할 수 있습니다.
- Pod 내에서 container 포트를 바꾸더라도, Service는 이를 추상화하여 연결합니다.
- Pod 안에서는 name+containerPort 조합으로 포트를 정의할 수 있습니다.
- Service는 targetPort로 이 포트를 지정합니다.
containers:
- name: app
ports:
- name: http
containerPort: 8080
---
apiVersion: v1
kind: Service
spec:
ports:
- port: 80
targetPort: http # ← 포트 번호가 아닌 'name'으로 지정!이렇게 설정하면 Pod의 포트를 8080 → 9090으로 바꾸더라도, Pod 안의 name: http 만 그대로 두면 Service는 여전히 연결됩니다.
이 방식은 유연하고 확장성이 좋기 때문에 실무에서 자주 사용됩니다.
HPA
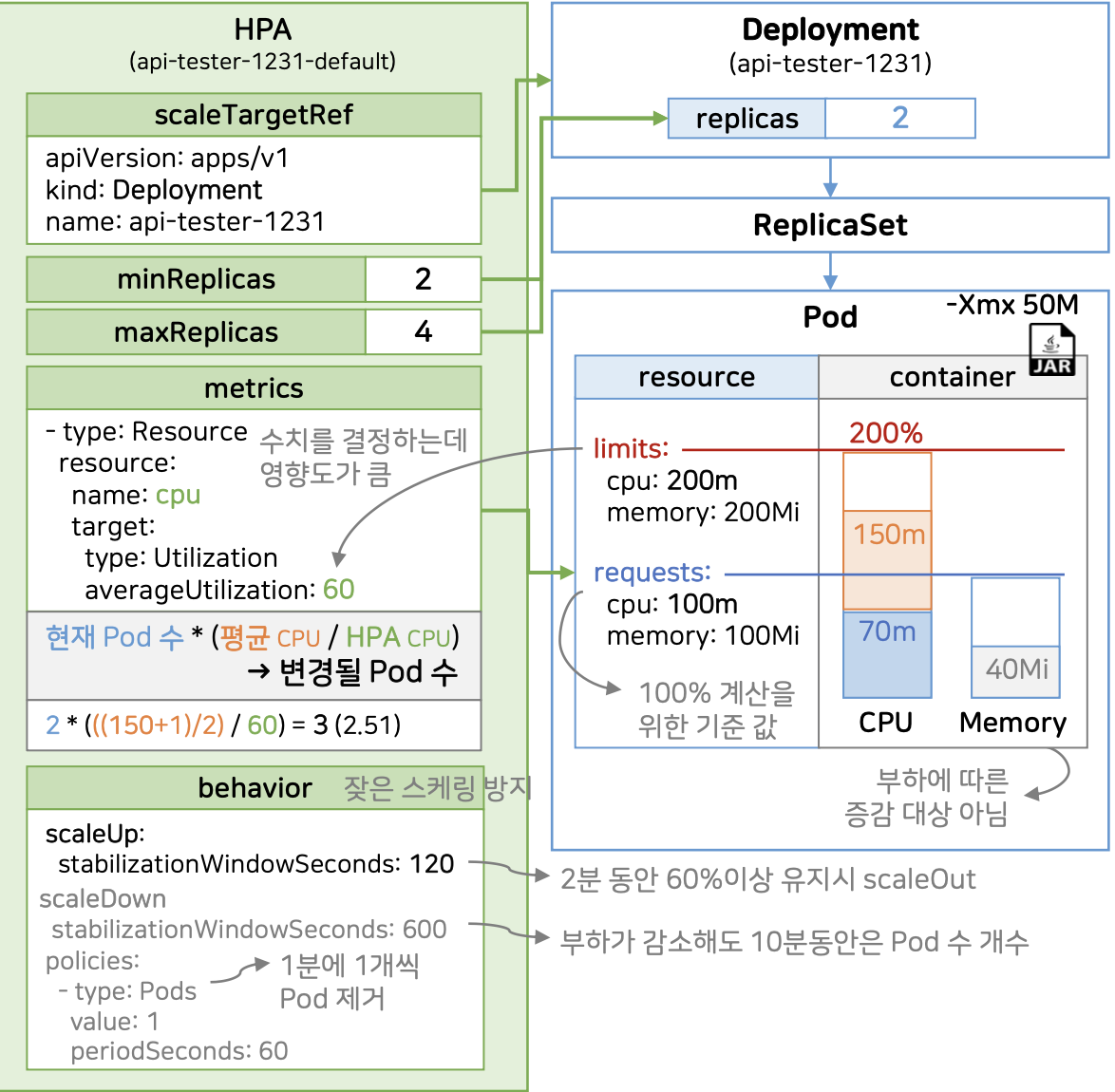
HPA는 쿠버네티스에서 Pod의 부하(CPU/메모리) 를 실시간으로 모니터링하고, 부하가 높아지면 Pod를 자동으로 늘리고, 부하가 낮아지면 줄여주는 오토스케일러입니다. 즉 Pod의 수를 수동으로 관리하지 않아도 됩니다.
| 감시 대상 | Deployment (api-tester-1231) |
| 기준 자원 | CPU (requests 기준, 60% 목표) |
| Pod 수 | 최소 2개, 최대 4개 |
| 계산 방식 | 현재 Pod 수 × (평균 CPU / 목표 CPU) |
| 스케일 조건 | 2분 이상 지속되면 증가, 10분 이상 유지돼야 감소 |
CPU 사용량을 주로 기준치로 사용할뿐 CPU 사용량만 보고 부하를 판단하는 것은 한계가 있습니다. 애플리케이션의 특성에 따라 DB 커넥션 수, 스레드 수, 큐 대기 길이, 응답 시간 등 부하를 판단하는 기준은 다양하기 때문입니다.
예를 들어, 어떤 웹 애플리케이션은 CPU는 낮지만 DB 커넥션이 포화되어 더 이상 요청을 처리하지 못할 수 있고, 반대로 CPU 사용률이 높아도 애플리케이션 레벨에서 적절히 처리되고 있다면 굳이 스케일아웃할 필요가 없을 수도 있습니다.
쿠버네티스에서는 HPA를 커스터마이징할 수 있도록 다양한 옵션을 제공합니다.
- Custom Metrics API 사용
- 외부 모니터링 시스템(Prometheus 등)과 연동하여
- DB 커넥션 수, 큐 길이, 사용자 정의 지표 등을 기준으로 스케일링 가능
- External Metrics 사용
- 쿠버네티스 외부 지표를 HPA의 기준으로 활용할 수 있음
- 예: 외부 Redis의 QPS, Kafka lag 등
- KEDA(Kubernetes-based Event Driven Autoscaler)
- Azure가 만든 오픈소스 프로젝트로, RabbitMQ, Kafka, Redis, Prometheus 등 다양한 외부 이벤트 소스로도 스케일링 가능
- 특히 비동기 기반 시스템에서는 KEDA가 더 적합한 경우도 많습니다.
기본적인 HPA 설정은 CPU/메모리 기준이지만, 실제 운영 환경에서는 애플리케이션의 특성에 맞는 지표를 선정하고, 이를 기반으로 커스터마이징한 오토스케일링 전략을 설계하는 것이 중요합니다.
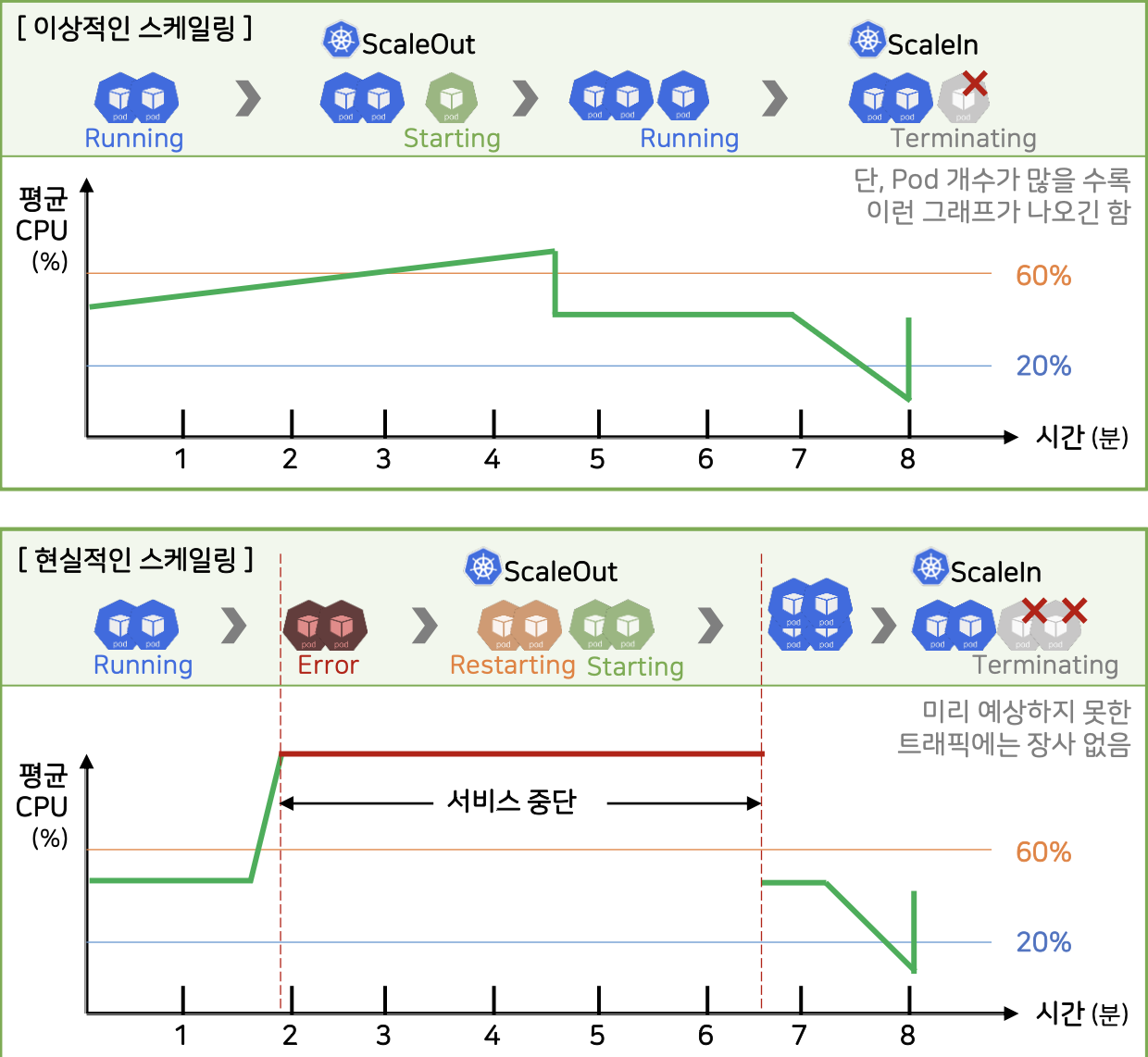
위 그래프를 보면 이상적인 경우에는 CPU 부하가 점진적으로 올라가고, 적절한 시점에 ScaleOut이 이루어지며 서비스에 영향 없이 대응할 수 있습니다. 하지만 현실적으로는 갑작스러운 트래픽 급증(Peak 시간대)에 대응하지 못해, Pod가 스케일아웃되기 전에 에러가 발생하거나 서비스가 중단되는 경우도 자주 발생합니다. HPA는 반응형 오토케스케일러이기 때문입니다. 즉, 부하가 올라간 후에야 Pod를 늘리기 시작합니다. Pod가 Starting 상태일 때는 아직 트래픽을 받을 수 없으므로 늘리기 시작했을 때는 이미 늦은 경우가 많습니다. 그래서 다음과 같은 전략을 취할 수 있습니다.
1. 트래픽 패턴을 예측하고, 미리 Pod를 늘려두기
HPA만 믿지 말고, CronJob 또는 ScheduledScaler 등을 활용해 미리 replicas 수를 증가시켜놓는 것이 효과적입니다.
2. Queue 기반 아키텍처 도입
API 서버가 트래픽을 모두 직접 처리하지 않고, Kafka, RabbitMQ, Redis 등으로 요청을 큐잉해두고, 백엔드 Worker Pod가 하나씩 처리하도록 설계하면 일시적인 트래픽 폭주에도 유실 없이 안정적으로 처리할 수 있습니다.
Pod 수가 아주 많고, 탄력적으로 대응 가능한 환경이라면 문제가 덜하겠지만, 대부분의 서비스는 자원도 제한되어 있고 예산도 존재하기 때문에 HPA + 사전 대응 전략을 함께 병행하는 것이 가장 이상적입니다.
'Infra' 카테고리의 다른 글
| [K8S] DevOps (0) | 2025.05.26 |
|---|---|
| [K8S] Component (0) | 2025.05.25 |
| [K8S] ConfigMap & Secret (0) | 2025.05.25 |
| [K8S] Probe (0) | 2025.05.20 |
| [K8S] 오브젝트 (0) | 2025.05.19 |




댓글