지난 포스팅에서 Elasticsearch가 무엇인지, 왜 사용하는지에 대해 알아보았습니다. 이번에는 실제로 Elasticsearch를 설치하고 사용하는 방법에 대해 자세히 알아보겠습니다.
Elasticsearch 설치 및 환경 설정
실습을 위한 설치는 간편하게 Docker로 간편하게 진행했습니다.
# Elasticsearch 이미지 다운로드
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.13.0
# 실행
docker run -d --name elasticsearch \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms2g -Xmx2g" \
-e "xpack.security.enabled=false" \
-p 9200:9200 \
docker.elastic.co/elasticsearch/elasticsearch:8.13.0Elasticsearch를 실행하게 되면, 보안 기능이 있습니다. 하지만 간단하게 테스트 용도이기 때문에 간편하게 보안 기능은 끄고 진행하겠습니다. 또, 기본적으로 Elasticsearch는 클러스터 구성을 시도합니다. 테스트 용도이기 때문에, 단일 노드만 실행하겠습니다.
이미지를 받고 정상적으로 실행을 하셨다면 간단하게 다음과 같은 명령어를 통해 Elasticsearch의 클러스터 이름, uuid, 버전 정보를 확인하실 수 있습니다.
curl -X GET "localhost:9200/"
인덱스 생성
curl -X PUT "localhost:9200/my_index?pretty" \
-H 'Content-Type: application/json' \
-d '{}'위의 명령어를 사용하면 새로운 인덱스를 생성할 수 있습니다. 인덱스 이름은 my_index이고, ?pretty옵션을 주면 Elasticsearch 서버가 저장될 json형태의 데이터들을 알아보기 쉽게 줄바꿈해줍니다. 하지만 터미널 명령어로 진행하게 되면 불편하므로, Postman을 사용하겠습니다.
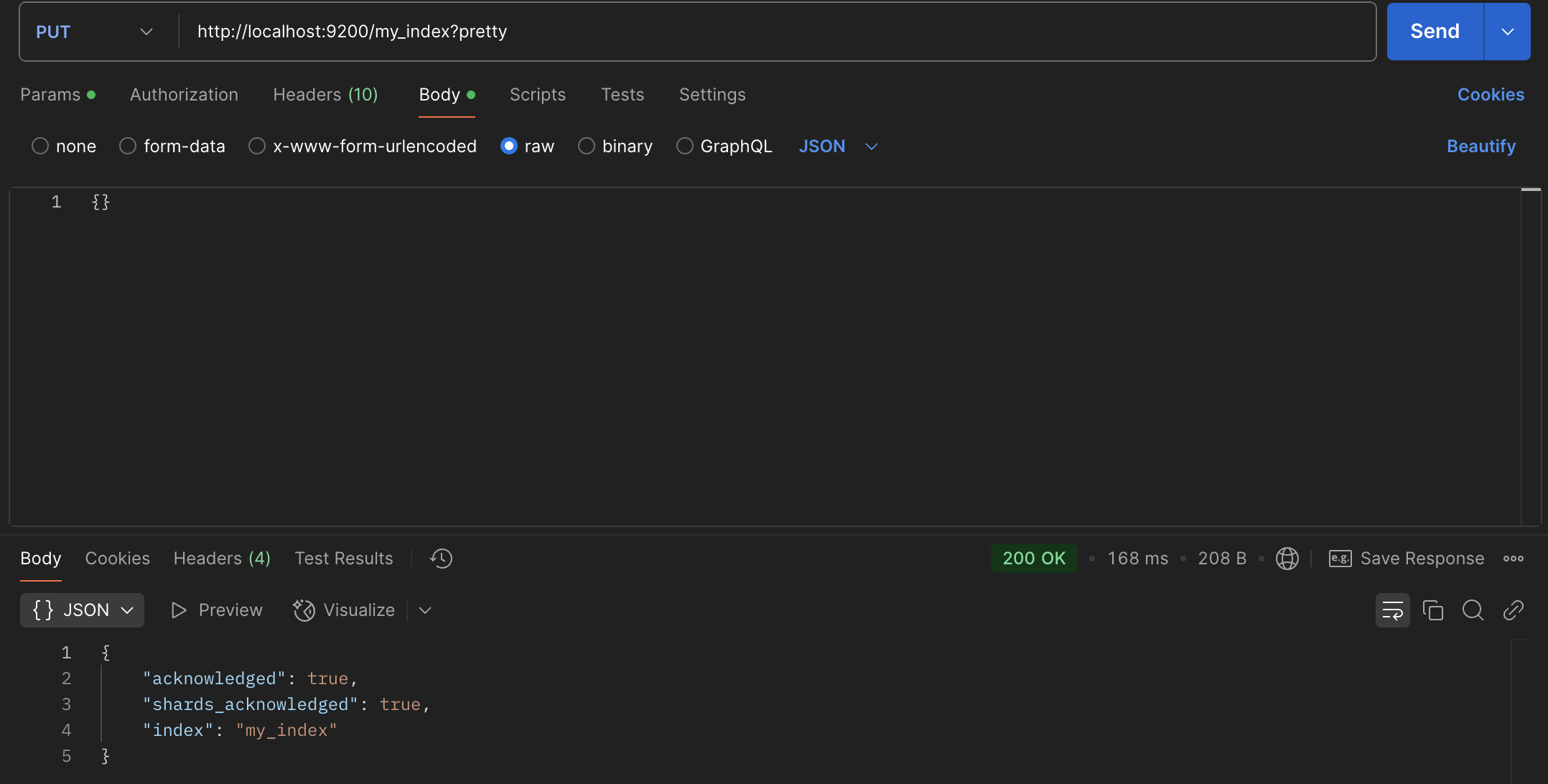
인덱스가 정상적으로 생성이 되면 서버로 부터 위와 같은 응답이 옵니다. 생성된 index는 똑같은 주소값으로 GET 요청을 통해 확인할 수 있습니다. 반대로 삭제는 DELETE 요청을 하시면 됩니다.
문서 생성
생성된 인덱스에 문서를 저장하려면 my_index/_doc 엔드포인트로 POST 요청을 보내면 됩니다.
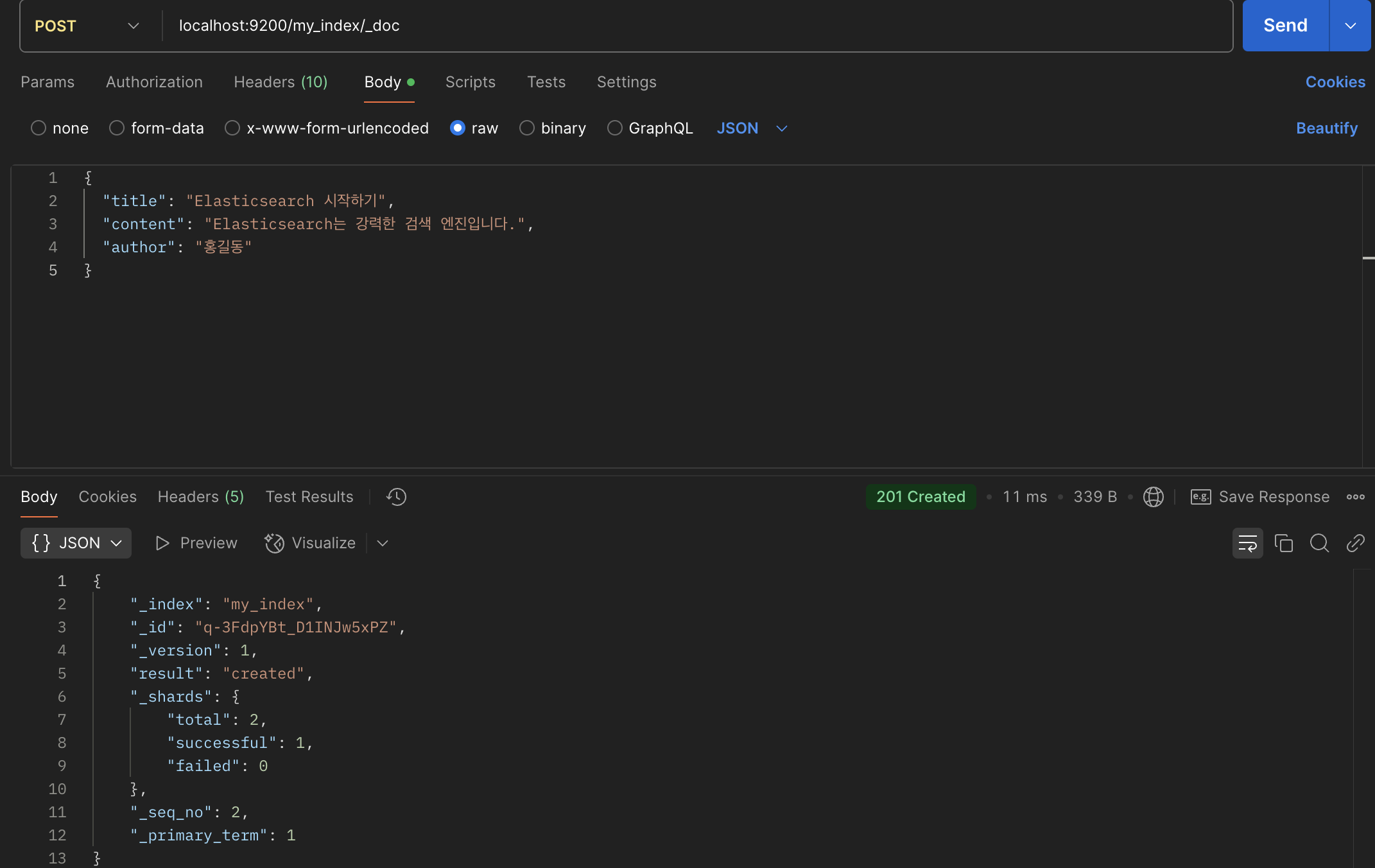
정상적적으로 생성되었다면 위와 같은 응답이 오는데, _id를 보면 랜덤한 값입니다. 요청시 엔드포인트에 /{id}를 추가해 id를 직접 지정할 수 있습니다.
생성된 문서는 간단하게 GET 요청으로 확인할 수 있습니다. 또한 삭제의 경우에도 DELETE 메소드로 간단히 진행할 수 있습니다.
❯ curl -X GET "localhost:9200/my_index/_doc/2?pretty"
{
"_index" : "my_index",
"_id" : "2",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "Elasticsearch 시작하기",
"content" : "Elasticsearch는 강력한 검색 엔진입니다.",
"author" : "홍길동"
}
}
수정(Update)의 경우 Elasticsearch는 문서를 불변(immutable)으로 취급하기 때문에, 모든 업데이트는 실제로는 기존 문서를 삭제하고 새 문서를 생성하는 방식입니다. 2가지 방법으로 업데이트를 할 수 있습니다.
1. _update API 사용 (부분 업데이트):
- 기존 문서의 일부만 수정됩니다.
- 내부적으로는 기존 문서를 읽고, 변경사항을 병합한 후, 새 문서로 대체하는 방식이지만 사용자 입장에서는 부분 수정처럼 보입니다.
POST /my_index/_update/1
{
"doc": {
"content": "수정된 내용"
}
}2. PUT 메서드로 전체 문서 교체:
- 기존 문서가 완전히 삭제되고 새 문서가 삽입되고 명시하지 않는 필드는 없어집니다.
PUT /my_index/_doc/1
{
"title": "새로운 제목",
"content": "완전히 새로운 내용"
}
부분 업데이트를 사용했을 때에는, 문서의 버전 정보가 변경됩니다.
{
"_index": "my_index",
"_id": "2",
"_version": 4.
.,
.,
}
검색
특정 인덱스에 포함된 문서를 검색하려면 다음과 같이 _search 엔드포인트로 요청하시면 됩니다.
GET "localhost:9200/my_index/_search?pretty"문서 내의 특정 필드의 값에 따라 필터링하고 싶다면 다음과 같이 body를 함께 넘겨주시면 됩니다.
{
"query": {
"match": {
"author": "kmk2"
}
}
}
매핑
매핑은 문서의 필드 타입을 정의하는 스키마입니다.
curl -X PUT "localhost:9200/blog_index?pretty" -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "standard"
},
"created_at": {
"type": "date"
},
"views": {
"type": "integer"
},
"tags": {
"type": "keyword"
}
}
}
}'
Elasticsearch의 매핑 동작 방식
- 동적 매핑(Dynamic Mapping):
- 매핑에 정의되지 않은 필드가 들어오면 자동으로 타입을 추론하여 매핑을 생성
- 기본적으로 활성화
- 엄격한 매핑(Strict Mapping):
- 매핑에 정의되지 않은 필드는 허용하지 않습니다.
- dynamic: "strict" 설정으로 활성화합니다.
// 동적 매핑 (기본값)
PUT /my_index
{
"mappings": {
"properties": {
"title": { "type": "text" }
}
}
}
// 새로운 필드 추가 시
POST /my_index/_doc/1
{
"title": "제목",
"content": "내용" // 매핑에 없지만 자동으로 추가됨
}
// 엄격한 매핑
PUT /strict_index
{
"mappings": {
"dynamic": "strict",
"properties": {
"title": { "type": "text" }
}
}
}
// 오류 발생
POST /strict_index/_doc/1
{
"title": "제목",
"content": "내용" // 오류! 매핑에 정의되지 않은 필드
}
이번 포스팅에서는 Elasticsearch의 기본적인 사용법에 대해 알아보았습니다. Docker를 통한 간편한 설치부터 인덱스 관리, CRUD 작업, 검색, 매핑 등 기본적인 기능을 다루었습니다. 감사합니다.
'Database' 카테고리의 다른 글
| PostgreSQL 클러스터 구성하기(2) (3) | 2025.06.18 |
|---|---|
| PostgreSQL 클러스터 구성하기(1) (2) | 2025.06.18 |
| Elasticsearch 디스크 워터마크 이슈 (1) | 2025.04.30 |
| Elasticsearch 개념 정리: 역인덱스 (0) | 2025.04.26 |
| 데이터베이스 이중화 구현: 마스터-슬레이브 복제 구축 (2) | 2025.04.25 |




댓글